 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevant Is Not Warranted: Evidence-Force Calibration for Cited RAG
May 27, 2026Cited RAG evaluation often treats visible sources as a grounding signal, but a real, topically relevant citation can still under-warrant the attached wording. We study this diagnostic failure as citation laundering: a related source is presented as warrant for an over-strong claim. We introduce FORCEBENCH, a contrastive stress test for evidence-force calibration. Each item holds a cited passage fixed and pairs an evidence-calibrated claim with a localized force-raised variant across five operational axes: relation, modality, scope, temporal validity, and numeric specificity. A calibrated evaluator should score the evidence-calibrated claim higher. Headline experiments use a fixed, locality-filtered 198-pair evaluation set. A citation-presence sanity check is uninformative by design; token and entity overlap still violate monotonicity on 32.8--36.4% of pairs. Across four reported model judges, standard generic support prompting is insufficient for this force-calibration stress test (aggregate MVR 47.2%), while explicit warrant-strength prompting lowers MVR to 24.5% but remains imperfect. We release the benchmark, prompts, outputs, and plug-in pipeline so citation evaluators can report monotonicity violation rate and force sensitivity alongside conventional support metrics.
Does RAG Know When Retrieval Is Wrong? Diagnosing Context Compliance under Knowledge Conflict
May 14, 2026The Context-Compliance Regime in Retrieval-Augmented Generation (RAG) occurs when retrieved context dominates the final answer even when it conflicts with the model's parametric knowledge. Accuracy alone does not reveal how retrieved context causally shapes answers under such conflict. We introduce Context-Driven Decomposition (CDD), a belief-decomposition probe that operates at inference time and serves as an intervention mechanism for controlled retrieval conflict. Across Epi-Scale stress tests, TruthfulQA misconception injection, and cross- model reruns, CDD exposes three patterns. P1: context compliance is measurable in an upper-bound adversarial setting, where Standard RAG reaches 15.0% accuracy on TruthfulQA misconception injection (N=500). P2: adversarial accuracy gains transfer across model families: CDD improves accuracy on Gemini-2.5-Flash and on Claude Haiku/Sonnet/Opus, but rationale-answer causal coupling does not transfer. CDD reaches 64.1% mistake- injection causal sensitivity on Gemini-2.5-Flash, while sensitivities for all three Claude variants fall in the [-3%, +7%] range, suggesting that the Claude-side accuracy gains operate through a mechanism distinct from the explicit conflict-resolution trace. P3: explicit conflict decomposition improves robustness under temporal drift and noisy distractors, with CDD reaching 71.3% on temporal shifts and 69.9% on distractor evidence on the full Epi-Scale adversarial benchmark. These three patterns identify context-compliance as a structural axis along which standard RAG can be probed and intervened on, distinct from retrieval-quality or single-method robustness questions, and motivate releasing Epi-Scale for systematic study across model families and retrieval pipelines.
Can RL Teach Long-Horizon Reasoning to LLMs? Expressiveness Is Key
May 07, 2026Reinforcement learning (RL) has been applied to improve large language model (LLM) reasoning, yet the systematic study of how training scales with task difficulty has been hampered by the lack of controlled, scalable environments. We introduce ScaleLogic, a synthetic logical reasoning framework that offers independent control over two axes of difficulty: the depth of the required proof planning (i.e., the horizon) and the expressiveness of the underlying logic. Our proposed framework supports a wide range of logics: from simple implication-only logic ("if-then") towards more expressive first-order reasoning with conjunction ("and"), disjunction ("or"), negation ("not"), and universal quantification ("for all"). Using this framework, we show that the RL training compute $T$ follows a power law with respect to reasoning depth $D$ ($T \propto D^γ$, $R^{2} > 0.99$), and that the scaling exponent $γ$ increases monotonically with logical expressiveness, from $1.04$ to $2.60$. On downstream mathematics and general reasoning benchmarks, more expressive training settings yield both larger performance gains (up to $+10.66$ points) and more compute-efficient transfer compared to less expressive settings, demonstrating that what a model is trained on, not just how much it is trained, shapes downstream transfer. We further show that the power-law relationship holds across multiple RL methods, and curriculum-based training substantially improves scaling efficiency.
Asset Harvester: Extracting 3D Assets from Autonomous Driving Logs for Simulation
Apr 20, 2026Closed-loop simulation is a core component of autonomous vehicle (AV) development, enabling scalable testing, training, and safety validation before real-world deployment. Neural scene reconstruction converts driving logs into interactive 3D environments for simulation, but it does not produce complete 3D object assets required for agent manipulation and large-viewpoint novel-view synthesis. To address this challenge, we present Asset Harvester, an image-to-3D model and end-to-end pipeline that converts sparse, in-the-wild object observations from real driving logs into complete, simulation-ready assets. Rather than relying on a single model component, we developed a system-level design for real-world AV data that combines large-scale curation of object-centric training tuples, geometry-aware preprocessing across heterogeneous sensors, and a robust training recipe that couples sparse-view-conditioned multiview generation with 3D Gaussian lifting. Within this system, SparseViewDiT is explicitly designed to address limited-angle views and other real-world data challenges. Together with hybrid data curation, augmentation, and self-distillation, this system enables scalable conversion of sparse AV object observations into reusable 3D assets.
LiDAR-EVS: Enhance Extrapolated View Synthesis for 3D Gaussian Splatting with Pseudo-LiDAR Supervision
Mar 16, 20263D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time LiDAR and camera synthesis in autonomous driving simulation. However, simulating LiDAR with 3DGS remains challenging for extrapolated views beyond the training trajectory, as existing methods are typically trained on single-traversal sensor scans, suffer from severe overfitting and poor generalization to novel ego-vehicle paths. To enable reliable simulation of LiDAR along unseen driving trajectories without external multi-pass data, we present LiDAR-EVS, a lightweight framework for robust extrapolated-view LiDAR simulation in autonomous driving. Designed to be plug-and-play, LiDAR-EVS readily extends to diverse LiDAR sensors and neural rendering baselines with minimal modification. Our framework comprises two key components: (1) pseudo extrapolated-view point cloud supervision with multi-frame LiDAR fusion, view transformation, occlusion curling, and intensity adjustment; (2) spatially-constrained dropout regularization that promotes robustness to diverse trajectory variations encountered in real-world driving. Extensive experiments demonstrate that LiDAR-EVS achieves SOTA performance on extrapolated-view LiDAR synthesis across three datasets, making it a promising tool for data-driven simulation, closed-loop evaluation, and synthetic data generation in autonomous driving systems.
A Tale of LLMs and Induced Small Proxies: Scalable Agents for Knowledge Mining
Oct 01, 2025At the core of Deep Research is knowledge mining, the task of extracting structured information from massive unstructured text in response to user instructions. Large language models (LLMs) excel at interpreting such instructions but are prohibitively expensive to deploy at scale, while traditional pipelines of classifiers and extractors remain efficient yet brittle and unable to generalize to new tasks. We introduce Falconer, a collaborative framework that combines the agentic reasoning of LLMs with lightweight proxy models for scalable knowledge mining. In Falconer, LLMs act as planners, decomposing user instructions into executable pipelines, and as annotators, generating supervision to train small proxies. The framework unifies classification and extraction into two atomic operations, get label and get span, enabling a single instruction-following model to replace multiple task-specific components. To evaluate the consistency between proxy models incubated by Falconer and annotations provided by humans and large models, we construct new benchmarks covering both planning and end-to-end execution. Experiments show that Falconer closely matches state-of-the-art LLMs in instruction-following accuracy while reducing inference cost by up to 90% and accelerating large-scale knowledge mining by more than 20x, offering an efficient and scalable foundation for Deep Research.
OccTransformer: Improving BEVFormer for 3D camera-only occupancy prediction
Feb 28, 2024



This technical report presents our solution, "occTransformer" for the 3D occupancy prediction track in the autonomous driving challenge at CVPR 2023. Our method builds upon the strong baseline BEVFormer and improves its performance through several simple yet effective techniques. Firstly, we employed data augmentation to increase the diversity of the training data and improve the model's generalization ability. Secondly, we used a strong image backbone to extract more informative features from the input data. Thirdly, we incorporated a 3D unet head to better capture the spatial information of the scene. Fourthly, we added more loss functions to better optimize the model. Additionally, we used an ensemble approach with the occ model BevDet and SurroundOcc to further improve the performance. Most importantly, we integrated 3D detection model StreamPETR to enhance the model's ability to detect objects in the scene. Using these methods, our solution achieved 49.23 miou on the 3D occupancy prediction track in the autonomous driving challenge.
Calibrating Cross-modal Feature for Text-Based Person Searching
Apr 05, 2023



We present a novel and effective method calibrating cross-modal features for text-based person search. Our method is cost-effective and can easily retrieve specific persons with textual captions. Specifically, its architecture is only a dual-encoder and a detachable cross-modal decoder. Without extra multi-level branches or complex interaction modules as the neck following the backbone, our model makes a high-speed inference only based on the dual-encoder. Besides, our method consists of two novel losses to provide fine-grained cross-modal features. A Sew loss takes the quality of textual captions as guidance and aligns features between image and text modalities. A Masking Caption Modeling (MCM) loss uses a masked captions prediction task to establish detailed and generic relationships between textual and visual parts. We show the top results in three popular benchmarks, including CUHK-PEDES, ICFG-PEDES, and RSTPReID. In particular, our method achieves 73.81% Rank@1, 74.25% Rank@1 and 57.35% Rank@1 on them, respectively. In addition, we also validate each component of our method with extensive experiments. We hope our powerful and scalable paradigm will serve as a solid baseline and help ease future research in text-based person search.
Symmetric Network with Spatial Relationship Modeling for Natural Language-based Vehicle Retrieval
Jun 22, 2022


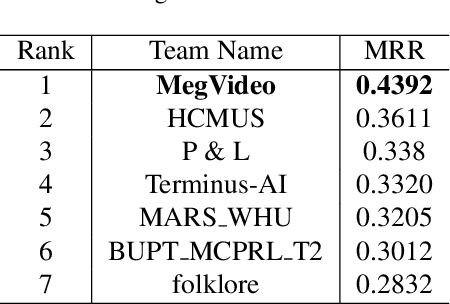
Natural language (NL) based vehicle retrieval aims to search specific vehicle given text description. Different from the image-based vehicle retrieval, NL-based vehicle retrieval requires considering not only vehicle appearance, but also surrounding environment and temporal relations. In this paper, we propose a Symmetric Network with Spatial Relationship Modeling (SSM) method for NL-based vehicle retrieval. Specifically, we design a symmetric network to learn the unified cross-modal representations between text descriptions and vehicle images, where vehicle appearance details and vehicle trajectory global information are preserved. Besides, to make better use of location information, we propose a spatial relationship modeling methods to take surrounding environment and mutual relationship between vehicles into consideration. The qualitative and quantitative experiments verify the effectiveness of the proposed method. We achieve 43.92% MRR accuracy on the test set of the 6th AI City Challenge on natural language-based vehicle retrieval track, yielding the 1st place among all valid submissions on the public leaderboard. The code is available at https://github.com/hbchen121/AICITY2022_Track2_SSM.
* 8 pages, 3 figures, publised to CVPRW